

When managing Jira Data Center instances, a series of factors must be considered and kept under control to guarantee a correct and sustainable software function over time. That's why we've compiled a list of Jira administration best practices, especially for the newbies, who'll find it valuable when working with Data Center instances.
Working with Jira could be an overwhelming task, especially if you're new to it and don't have any background about the do's and don'ts, not to mention the immensity of Jira's basic concepts. It's a software tool that allows you to do a lot and leaves carte blanche to use the method that best suits you and how your team works.
Achieve a successful implementation of Jira following these tips >>
One of the significant advantages of Jira is allowing it to achieve the same result in different ways. Our experiences as Atlassian consultants have taught us that, at least, these following tips should be a must for every Jira Data Center Administrator -at a functional level, without getting into the actual system administration.
These Jira best practices will specifically help less experienced Jira Data Center administrators. Through this simple "guide," you'll learn how to identify, in broad terms, those situations where "Custom Fields" should be created, how to reuse items such as issue types, custom fields, and workflows, also how to standardize naming conventions of our items/schemas, and some general tips on archiving issues. Let's get into it:
As any Jira instance grows and extends to other areas, the need for new custom fields is often imperative. However, having too many custom fields can saturate our instance (and your human brain!). To establish a rational criterion in certain situations, we give you some parameters::
These last two options allow for identifying the unused fields and taking the necessary measures.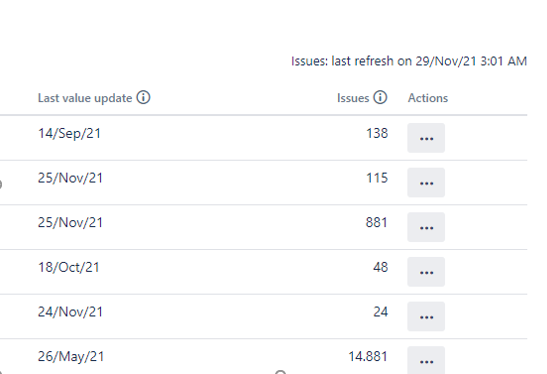
Here are the values of the last update and the number of Jira issues where a custom field is used.
In Jira, it's possible to have multiple schemes, screens, workflows, etc., and it's simple to create chaos within our instance because of them. That's why here's the thing, try to mitigate it by establishing a couple of naming rules.
First, you should ask yourself whether the object will be used in a single project or shared with others.
We recommend you start with the project key and describe the object type for the first option.
For instance, imagine a marketing project using the key MKT, where we'll have a workflow and a default screen layout for all types of "Issue" except for the "Task." We could use something like this:
|
Issue type scheme |
Workflow scheme |
Workflows |
|
|
|
| Screen layout by issue type |
Screen layout |
PScreens |
|
|
|
For the second option, let's suppose we've two options to carry out our development projects; these configurations are shared with multiple projects using templates, as we'll see in point number three.
In this case, we'll not use the project key as the suffix for configuration options as each of these is used by multiple projects.
For these types of projects, we could add the suffix "DEV," then the type of project, and end it with the object's description.
For example, for the type scheme of "Issue," we could use:
|
Projects A |
Projects B |
|
|
With this solution, we'll see a clean and organized scheme when navigating through the options in the Jira administration since it's in alphabetical order.
Learn how we created an extensive catalog of options in Jira for a large banking company >>
Although Jira comes with a series of standard projects, these projects may not be adapted to our needs in many cases. To overcome this, we can generate our own "template" projects.
Atlassian products appreciate when sharing the different configuration options within a project (schemas, issue types, templates, etc.). In short, we can generate a set of different configurations to create different types of projects and thus meet the needs of our organization's other teams or processes.
To create a project based on a template, we must perform the following actions:
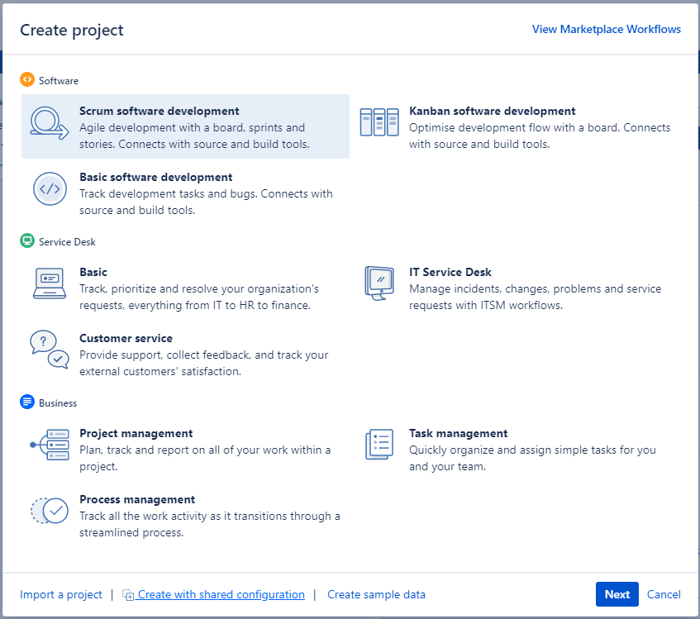
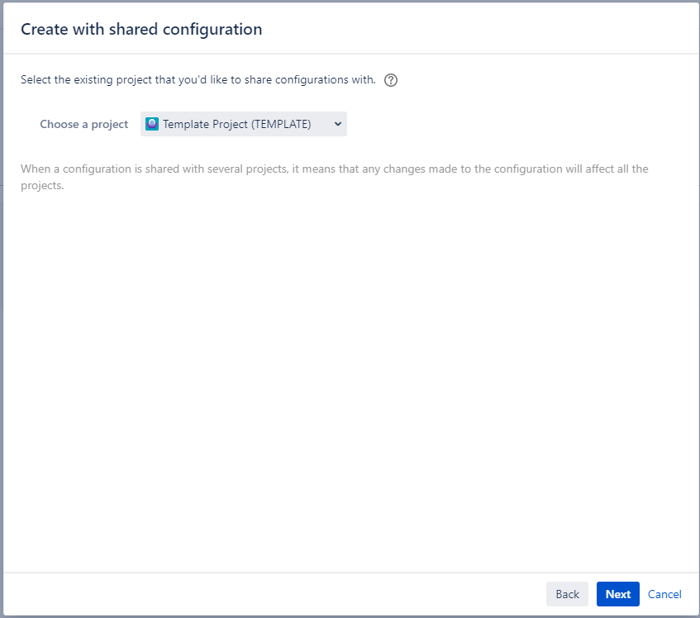
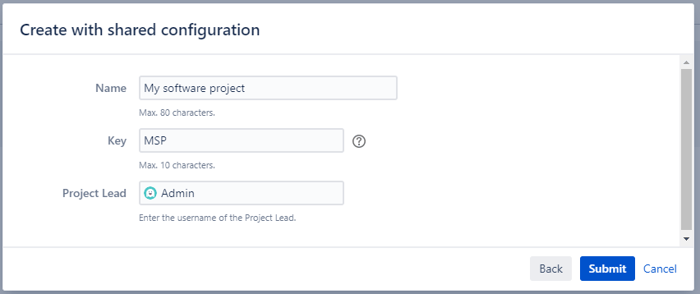
As in Jira, there are different ways to achieve the same goal; another way to keep your project catalog organized could be by using Atlassian's Marketplace apps.
Another helpful tip is about archiving "Issues." If we have a large volume of "Issues," and we need to keep them audited in the future, there's a handy Jira feature for these situations. But first, keep in mind the following:
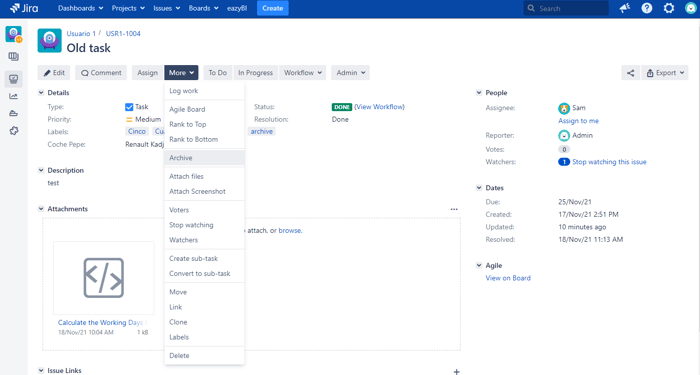
If, on the other hand, you need to archive multiple issues without selecting them one by one, you can use the bulk changes. To do so, you should:
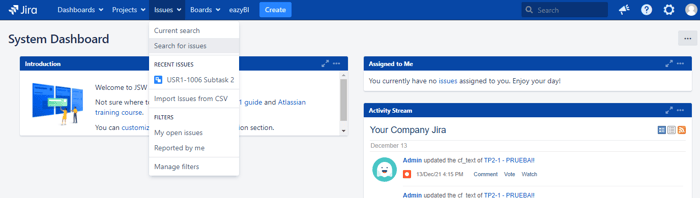
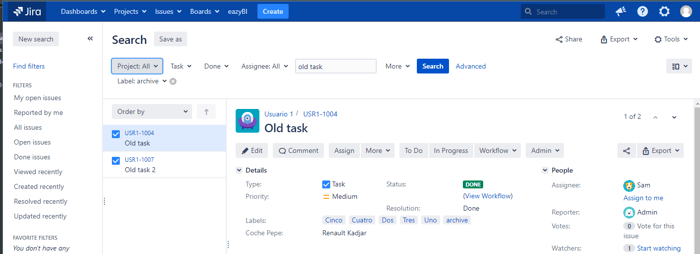
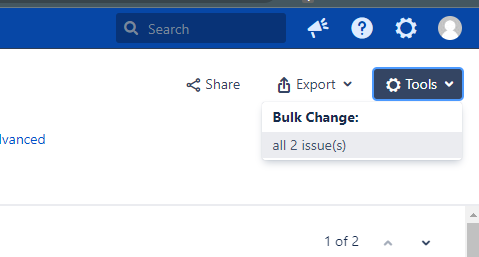
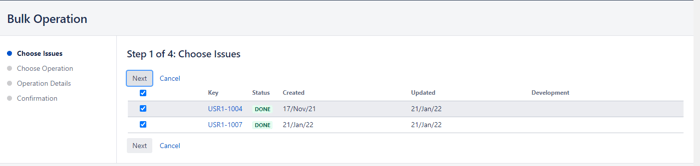
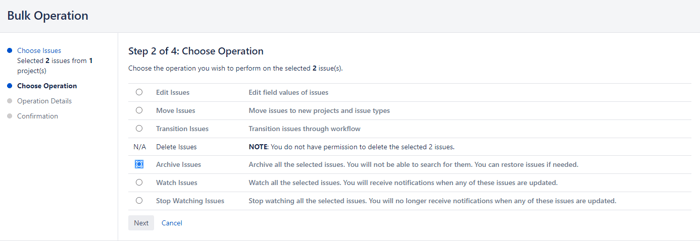
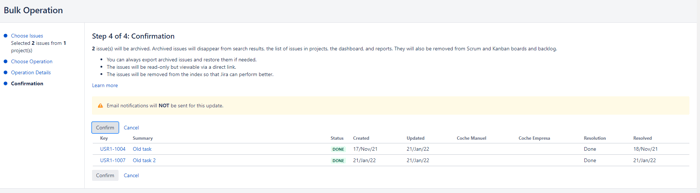
This section will discuss the importance of Jira's Resolution field. In many cases, it's mistakenly believed that an issue has been closed depending on its current state. When we have an issue in "Done" or "Close" status, it will be so, but internally, for Jira, an Issue has finished its life cycle when the Resolution field has a value.
Bad practices preach having an issue with a "Close" status has no value in the Resolution field. To check if this is happening in your workflows, perform a JQL search that will show all the "Issues" with this problem. For instance:
To solve this problem, it's necessary to correct the workflow by adding a screen requesting the Resolution field when moving to the final state or including a Post-Function in the transition leading to the final state, e.g., "Update Issue Field."

Also consider, if an issue can be reopened, we'll have to clean the value of that field. For this, it's advisable to create a Post-Function in that transition. We can reuse the Post-Function: "Update Issue Field."
Choose the Resolution field and name it None:

Once done, we'll have our workflows ready, and we'll not have this problem in future issues, but... What happens to tickets that have already been created and are closed?
There are several options:
If we have the ScriptRunner app, it has a "Built-In Script" called "Bulk Fix Resolution" that will allow us to give a value to this field based on a JQL filter previously saved.
However, if we do not have this app, we can perform the following operation:
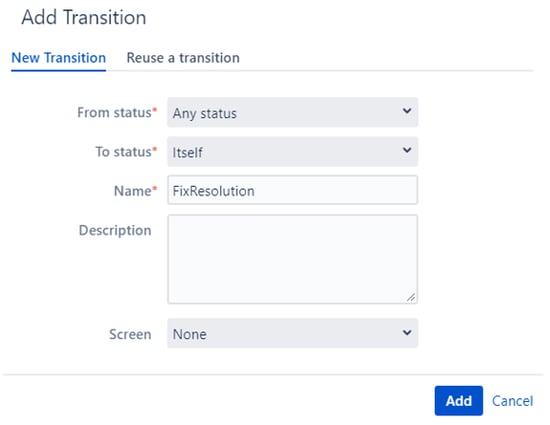
Now we'll have to add the Post-function ("Update Issue Field") to the transition we've created before, assigning a value to the "Resolution" field.
Additionally, we recommend adding a condition. This way, only administrators can execute this transition, and users won't be able to run this transition -to avoid mistakes.
Once the transition is created, we execute it. If we have multiple issues affected, we "Bulk change" them. To do this:
IMPORTANT: The resolution date is automatically updated in Jira's issues when you set a resolution, so the value will be the time when the fix is executed.
As you have seen, there are a lot of situations you have to face when working with Jira and facing uncertainty, it's best to have the best possible solution at hand. We hope you find these tips for Jira Data Center implementations useful.
If you are looking for more information about different ways to export Issues from Jira or more tips when implementing Jira or other blockers, don't hesitate to visit our blog; here, you'll find different solutions. For now, if you need more help, please get in touch with us by clicking the button below:








No Comments Yet
Let us know what you think